Linux 内核性能演变
本文是我在《系统设计与实现》课程的热点话题阅读报告,内容来源于 Xiang (Jenny) Ren, et al. 发表在 SOSP 2019 的论文《An Analysis of Performance Evolution of Linux’s Core Operations》(下文简称 [Ren19])。
1991年9月17日,赫尔辛基大学的大四学生 Linus Torvalds 向 ftp.funet.fi 上传了自己课余时间编写的 Linux 0.01 源代码,由此揭开了开源操作系统的崭新篇章。如今,Linux 已成为最主流的服务器操作系统,TOP500 榜单中的超级计算机更是悉数采用。在高性能计算对 Linux 依赖越来越强的大背景下,[Ren19] 对近年来 Linux 内核的核心操作性能进行了系统性的评估,得到一个骇人听闻的结论:绝大多数内核操作的性能均有退化。不过值得庆幸的是,研究团队发现可以通过编译配置或是简单的补丁来禁用掉那些导致性能退化的内核改动。
[Ren19] 之所以选择对内核操作(包括 epoll 等系统调用以及上下文切换等)进行分析,是因为随着硬盘读写和网络设备速度的提升,今后服务器的性能瓶颈可能会是操作系统的内核操作。以前相关的操作系统性能研究大多着眼于不同处理器架构上的性能差异,而如今 x86-64 架构已经一统天下了,因此保持硬件参数不变对操作系统进行时间尺度的分析更具有现实意义。研究团队基于 Ubuntu 发行版的默认配置,选取了 Linux 内核 3.0 到 4.20 共 41 个版本进行了基准测试,它们的发布时间横跨 2011 年到 2018 年。为了确定哪些是实际场景中常用的系统调用,研究团队用 strace 命令统计了 Spark、Redis、PostgreSQL、Chromium 和 GCC 等典型应用的计算任务,从中选取了八组总用时最多的内核操作进行基准测试。
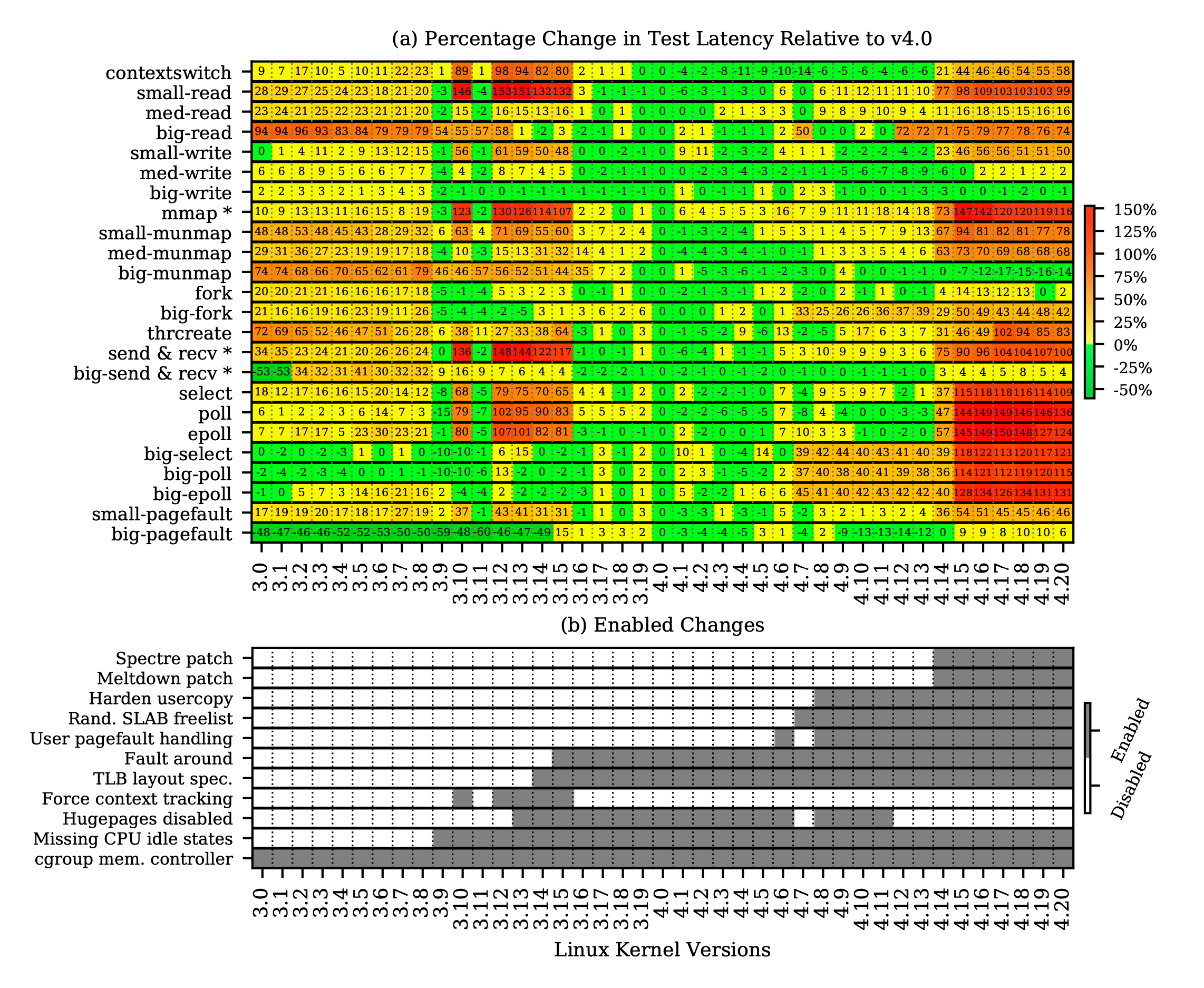
基准测试的最终结果如上图 (a) 所示:以 4.0 版本的内核为基准,除了 big-write 和 big-munmap 之外的所有内核操作都不同程度地变慢了,其中退步最大的 poll 甚至比之前慢了 136%。为了找出导致这些内核操作性能退化的原因,研究团队调查了 Linux 内核各版本之间的代码变化,最终确认了 11 处关键性改动,如上图 (b) 所示。这些严重影响了 Linux 内核性能的改动可以被归为三类:安全补丁、新增特性和错误配置。
不过在解释这些导致性能退化的原因之前,我们先盘点一下研究团队筛选出的内核操作都有哪些。
内核操作
- 上下文切换:当中断发生时,系统需要将当前进程的状态保存进进程控制块(PCB),以便处理器切换到下一个进程。该测试让两个进程通过管道不停地互相通信,以强制进行上下文切换。
read/write:读写文件。为了测试不同规模文件的读写性能,文件大小定为了一、十、万页三个档次(1 页 = 4096 字节)。mmap/munmap:将文件映射到内存,或取消其映射。测试文件大小同上。fork:创建一个跟自身一样的新进程。big-fork 在进程复制前映射了 12000 页文件。- 线程创建:使用 POSIX threads 创建线程(本质上是 Linux 轻量级进程)。
send/recv:使用 Berkeley sockets 进行本地进程间通信。select/poll/epoll:均为 Reactor 模式的 I/O 多路复用(multiplexing)机制,select和poll列入了 POSIX 标准但性能不够好,而新的epoll于 Linux 2.5.44 加入。- 缺页:当进程试图访问其地址空间中的数据时,若内存管理单元(MMU)发现该虚拟地址尚未映射到内存,则会触发缺页中断。该测试会访问刚刚
mmap上来的页,触发缺页让系统真正把文件从硬盘拷贝到内存。
盘点了基准测试中的内核操作之后,让我们按照分类逐一解释导致 Linux 内核性能退化的原因。关于头两个补丁所涉及的幽灵和熔毁漏洞的详细介绍,可以参考我之前的文章。
安全补丁
幽灵补丁1
第一个安全补丁针对的是 Spectre-V2 的分支目标注入,其为 Linux 内核编译配置加入了默认开启的 RETPOLINE 选项。该选项会向 GCC 添加 -mindirect-branch=thunk-extern 参数,从而绕过处理器对间接跳转指令的预测执行。该补丁让半数测试慢了 10% 以上,而影响较为严重的 select 一下子慢了 68%。研究团队对其中的原因进行了调查,发现 select 系列函数的代码有三处频繁执行的间接跳转,譬如其中一处位于 fs/select.c(4.18 版本之前):
static int do_select(...)
{
for (;;) {
mask = (*f_op->poll)(f.file, wait);
}
}
我们可以看到这里的 f_op->poll 是个函数指针,因此该函数调用会被编译为间接跳转指令。因为我们通过编译选项愚弄了分支预测器,导致每次都会有三十多个时钟周期的延时,这也就是 select 系列函数变慢的原因。研究团队尝试用 if-else 枚举函数指针所有可能的值,将间接跳转改为了直接跳转,成功地将减速比从 68% 降到了 5.7%。
熔毁补丁1
第二个安全补丁针对的是臭名昭著的 Meltdown 漏洞,也就是广为人知的内核页表隔离(KPTI)补丁。为了防止恶意程序读取任意内存数据,KPTI 分离了用户态和内核态的页表,用户态无法再访问绝大部分内核地址空间。KPTI 最大的开销来源于进出内核态需要切换页表和清空转译后备缓冲器(TLB),这包括页表指针寄存器(CR3)的两次写入和 TLB 的大量未命中。以前进出内核态的开销少于 100 个时钟周期,而 CR3 写入带来了 400 多个周期的开销,而后续 TLB 未命中的中断处理程序能为 big-read 带来 6000 个周期的额外开销。
为了改善这种情况,Linux 内核开发者利用英特尔处理器的上下文标识符(PCID)避免了每次清空 TLB:不同的 PCID 对应不同的地址空间,每个 TLB 条目可以附上 PCID 以同时管理多个地址空间的页表缓存。PCID 优化给 KPTI 带来了巨大的性能提升,能将小规模测试的减速比从 113% 从 47%,不过这无法优化掉 CR3 写入的开销,因为当前活跃的 PCID 仍需写入 CR3 寄存器。
如果对于性能有极致的追求,想要彻底关掉 KPTI,有两种办法:一是编译内核的时候就在配置中关掉 PAGE_TABLE_ISOLATION,二是在内核启动参数中加上 nopti。AMD 的用户则完全不必担心,因为 Meltdown 攻击完全不影响 AMD 处理器,所以 KPTI 已被自动禁用了。
Slab 自由表随机化2
Slab 分配器最初是为 SunOS 内核数据结构设计的内存分配器,如今被 Linux 和 FreeBSD 等操作系统广泛使用,譬如 fork 就在用它来分配 mm_struct 对象。Slab 分配器使用一个自由表(free list)串联未分配的内存区域,因为邻接的往往都是连续的内存地址,因此这种可预测性容易被用来进行缓冲区溢出攻击。从 Linux 4.7 开始,编译配置加入了 SLAB_FREELIST_RANDOM 选项,启用后会用 Fisher-Yates 随机排列算法打乱自由表的顺序。不过安全性也伴随着性能的代价,big-fork 变慢了 37%,big-select 系列函数平均变慢了 41%,这背后有两个原因:一是随机化自由表本身需要时间,二是不连续分配的内存破坏了访存局部性。
用户空间拷贝强化检查3
Linux 内核代码常常需要在内核空间和用户空间之间拷贝数据,这就需要用到 copy_from_user 和 copy_to_user 两个函数。如果内核开发者没有处理好相关调用,从用户空间拷贝了过多数据会导致缓冲区溢出,向用户空间拷贝了过多数据会造成内核空间数据泄漏。之前这两个函数只检查用户空间指针,从 Linux 4.8 引入的 Hardened Usercopy 补丁开始,内核空间指针也会进行非常严格的安全性检查,包括不允许为空指针、不允许指向 kmalloc 分配的零长度区域、不允许指向内核代码段、如果指向 Slab 则不允许超过 Slab 分配器分配的长度、如果涉及到栈则不允许超出当前进程的栈空间等等。这些繁琐的检查使得 select/poll 测试变慢了将近 18%,不过 epoll 很少进行拷贝所以影响不大;而 read 虽然会向用户空间拷贝数据,但由于不是 Slab 所以也几乎不受影响。
新增特性
控制组内存控制器4
控制组(cgroups)及其内存控制器早在 Linux 2.6.24 就引入了,这也是 LXC 和 Docker 等容器化技术的基础之一。不过即使在没有使用控制组功能时,内存控制器对内存使用额的监控工作仍然造成了 big-munmap 81% 的性能损失。直到 Linux 3.17,内核开发者才对其做了批处理的优化,将性能损失降到了 9%。
透明大页5
饱受争议的透明大页(transparent hugepage)也是影响访存性能的一大因素。众所周知,页是虚拟内存管理的最小单位,通常一页默认是 4KiB,但也可以手动设定为诸如 2MiB 的大页。不过由于手动管理页的大小比较麻烦,于是 Linux 等操作系统提供了透明大页功能,系统能够自动提升或下调页的大小。积极来讲,大页能够减少页表占用空间、降低缺页频率、并且能提高 TLB 命中率,对于大量使用内存的程序来说会有性能提升;然而另一方面,透明大页容易导致内部碎片化,低缺页率的代价是每次缺页加载时间显著增加,并且其后台进程也带来了额外开销。如今透明大页已经被默认禁用了,但禁用透明大页给极端的内存密集型测试 huge-read 带来了 83% 的性能退化。
缺页的局部性原理6
Linux 3.15 新增的 fault around 策略旨在减少次要缺页(minor page fault)。如果当前请求的这一页没有页表项,但实际上已经装进页缓存了,只需通知 MMU 建立映射关系即可,则这种缺页被称为次要缺页。在遇到次要缺页时,Linux 不仅会处理当前页,还会帮前后的若干页都建立映射关系。当然,这种优化策略是建立在访存局部性的基础之上的,像 big-pagefault 这种极端的不满足局部性的测试,就出现了高达 54% 的性能退化。
用户空间缺页处理7
Linux 4.6 新增的系统调用 userfaultfd 支持了在用户态处理指定范围内的缺页,这对于用户态的虚拟机监视器(VMM / Hypervisor)相当有帮助。譬如在进行虚拟机迁移之后,VMM 可以通过 userfaultfd 按需拷贝内存页,这种模式被称为 post-copy。不过 big-fork 由于这个新特性损失了 4% 的性能,因为在进程复制时需要检查父进程内存区域关联的用户空间缺页处理信息。
错误配置
强制上下文追踪
在 Ubuntu 发行版中,Linux 内核编译配置中的 CONTEXT_TRACKING_FORCE 选项曾被错误开启,这是在开发降低调度时钟滴答频率8(RSCT)功能时用来测试上下文追踪的调试选项。时钟滴答(tick)本质上就是定时器芯片产生的时钟中断,源源不绝的时钟中断为更新系统时间、执行进程调度提供了时机,但在处理器闲置时过于频繁的中断会增加功耗,而且在运行单个计算密集型程序时会造成干扰。因此,Linux 内核编译配置提供了三种 RSCT 选项(选项中的 HZ 意为每秒的时钟中断数,Linux 目前默认为 250):
HZ_PERIODIC表示永不忽略时钟滴答;NO_HZ_IDLE表示在处理器闲置时忽略时钟滴答,这是默认选项;NO_HZ_FULL表示在处理器闲置或只有一个可执行的任务时忽略时钟滴答,建议只在进行实时计算或某些高性能计算任务时开启此选项。
在开启了 RSCT 后,平时在时钟中断时做的工作就得挪到用户态和内核态切换的时候做,这些工作就被称为上下文追踪。这些工作包括统计在用户态和内核态的执行时间,以及处理 read-copy-update 同步机制注册的回调。强制上下文追踪会在所有处理器核心上都进行上下文追踪,不管有没有开启 RSCT,这导致前面的所有测试平均变慢了 50%。
CPU 闲置状态
Linux 3.9 为英特尔处理器的 Haswell 架构(研究团队在用)引入了一个补丁,让内核的驱动模块能够更加细粒度地控制处理器的功耗和闲置状态。不过这个补丁并没有移植到当时尚未停止维护的旧版本上,导致之前的版本容易陷入更深的闲置状态从而降频,打了补丁能将有效工作频率提高 31%。
TLB 大小识别
Linux 3.14 又为英特尔处理器引入了一个补丁,能够识别其二级 TLB 的大小以对 munmap 的实现进行优化。munmap 时让 TLB 项失效有两种策略:一是就处理那些失效项,二是清空整个 TLB。在这个补丁之前,只有一级 TLB 的大小会被纳入考虑,导致只要超过一项就会清空整个 TLB,大大降低了之后页表缓存的命中率。
结语
研究团队通过时间维度上的对比分析,揪出了 11 条造成 Linux 内核性能退化的原因,其中 88% 的影响是强制上下文追踪、熔毁补丁、粗粒度 CPU 闲置状态、幽灵补丁四项导致的。因为错误配置属于可以避免的人为错误,而新增特性对性能的影响面并不大,所以真正给 Linux 性能带来致命一击的就是幽灵系列漏洞的安全补丁。所以说,预测执行是一把双刃剑,想要绝对的安全就不得不放弃性能。
另外,正如研究团队所说,内核性能调优是个相当费时费力的工作。如果没有大量的精力投入到 Linux 这个快速迭代的庞然大物上,还是购买 RHEL 等高度调优的商业发行版更加划算。