幽灵・熔毁・预兆
去年肆虐了一年的幽灵系列漏洞似乎已经风平浪静了,但实际上它们对 CPU 微架构和系统软件领域依然有着长久而深远的影响。幽灵系列漏洞针对的并不是某个具体的硬件缺陷,而是将矛头对准了分支预测和乱序执行这两个现代 CPU 普遍采用的优化策略,并通过缓存旁路攻击完成对机密数据的任意读取,通用性极强,也极难做到全面的防御。本文将从幽灵系列漏洞的原理入手,介绍它们对现代计算机系统产生的影响和目前可行的对策。
幽灵系列漏洞截至目前至少已有十种变体被通用漏洞披露(CVE)数据库收录,亦有未被单独收录的 SpectreRSB(USENIX WOOT 2018)、ret2spec(ACM CCS 2018)等攻击被陆续发现。
| 漏洞编号 | 代号 | 正式名称 | |
|---|---|---|---|
| Variant 1 | CVE-2017-5753 | Spectre-V1 | Bounds Check Bypass |
| Variant 2 | CVE-2017-5715 | Spectre-V2 | Branch Target Injection |
| Variant 3 | CVE-2017-5754 | Meltdown | Rogue Data Cache Load |
| Variant 3a | CVE-2018-3640 | Spectre-NG | Rogue System Register Read |
| Variant 4 | CVE-2018-3639 | Spectre-NG | Speculative Store Bypass |
| - | CVE-2018-3665 | LazyFP | Lazy FP State Restore |
| - | CVE-2018-3693 | Spectre 1.1 | Bounds Check Bypass Store |
| - | CVE-2018-3615 | Foreshadow | L1 Terminal Fault - SGX |
| - | CVE-2018-3620 | Foreshadow-NG | L1 Terminal Fault - OS/SMM |
| - | CVE-2018-3646 | Foreshadow-NG | L1 Terminal Fault - VMM |
熔毁(Meltdown)
熔毁漏洞又称幽灵变体三,是这一系列漏洞中最容易利用、也最为人所知的一个。它由来自 Google Project Zero、德国 Cyberus 技术有限公司和奥地利格拉茨科技大学的三个团队各自独立地发现,论文发表在 USENIX Security 2018 上。要解释清楚熔毁漏洞的原理,需要综合三方面的知识:虚拟内存、乱序执行、基于缓存的旁路攻击。
我们都知道,现代的操作系统都应用了虚拟内存(Virtual Memory)技术,也就是说每个进程都拥有自己的虚拟地址空间,操作系统会根据页表将这些虚拟地址映射到物理地址。虚拟地址空间通常划分为用户和内核两部分,应用程序只能访问各自的用户地址空间,而只有在内核态下才能触及内核地址空间。为了进行访问权限控制,页表项中会有一个 User/Supervisor 位用来指定用户态能否访问,起到了隔离用户空间和内核空间的作用。在 Linux 和 macOS 等主流操作系统中,为了方便系统的访存操作,整个物理内存会直接映射到一部分内核空间上。而熔毁漏洞的目标便是攻破上述安全防线,在用户态也能任意访问所有物理内存。
为了达到目的,熔毁漏洞选择了从处理器的微架构着手攻击。现代处理器普遍采用了指令级并行技术来最大程度地发挥计算性能,其中一个特性便是乱序执行(Out-of-Order Execution)。在支持乱序执行的处理器上,所有指令在译码后将发往保留站(Reservation Station),一旦操作数就绪指令即可执行,不管先来后到。不过为了保证程序的正确性,指令执行的结果将以取指顺序写回程序员可见的寄存器,这被称为顺序提交(In-Order Commit)。而处理器的错误检测和异常处理都在提交阶段进行,如果发生异常则清空流水线并恢复原来的状态。
旁路攻击又称侧信道攻击(Side-Channel Attack),指绕开对加密算法的理论分析,而利用其硬件实现泄露的信息来进行攻击,譬如用时、功耗、电磁辐射等。在熔毁漏洞的例子中,缓存充当了攻击的旁路,基于缓存的 Flush+Reload 攻击击溃了乱序执行的最后一道防线。简单来讲,Flush+Reload 攻击首先利用 clflush 等指令预先清空缓存,再等待受害程序进行访存操作,然后通过数据访问的用时来判断某段数据在此期间是否被受害程序访问过。因为访问过的数据会载入缓存,所以下一次访问的速度会是第一次的两倍以上。如果没有权限调用 clflush 等指令,也可以手动访问大量无关数据来达到清空缓存的目的,这种变体被称为 Evict+Reload 攻击。
现在我们已经集齐了三片拼图,是时候把它们组合起来了。首先我们构造这样一段代码:
char data = *(char*)0xffffffff81a000e0;
char tmp = array[data * 4096];
我们可以看到第一行访问了一个内核空间的地址,理论上会因无权访问而触发段错误,从而中止程序的运行。然而我们之前提到错误检查是在提交阶段才进行的,于是第二行的代码有很大概率会在读到 data 之后到触发异常之前的时间窗口内提前执行。虽然这种乱序执行最终不会对寄存器有任何可见的影响,但容易被忽略的一点是,array 的部分数据被载入了缓存。虽然我们无法读取缓存中的数据,但我们可以通过 Flush+Reload 攻击来判断是 array 的哪部分被载入了缓存,从而得知 data 的值是多少。比如我们可以根据下图的用时曲线推断出 data = 84:
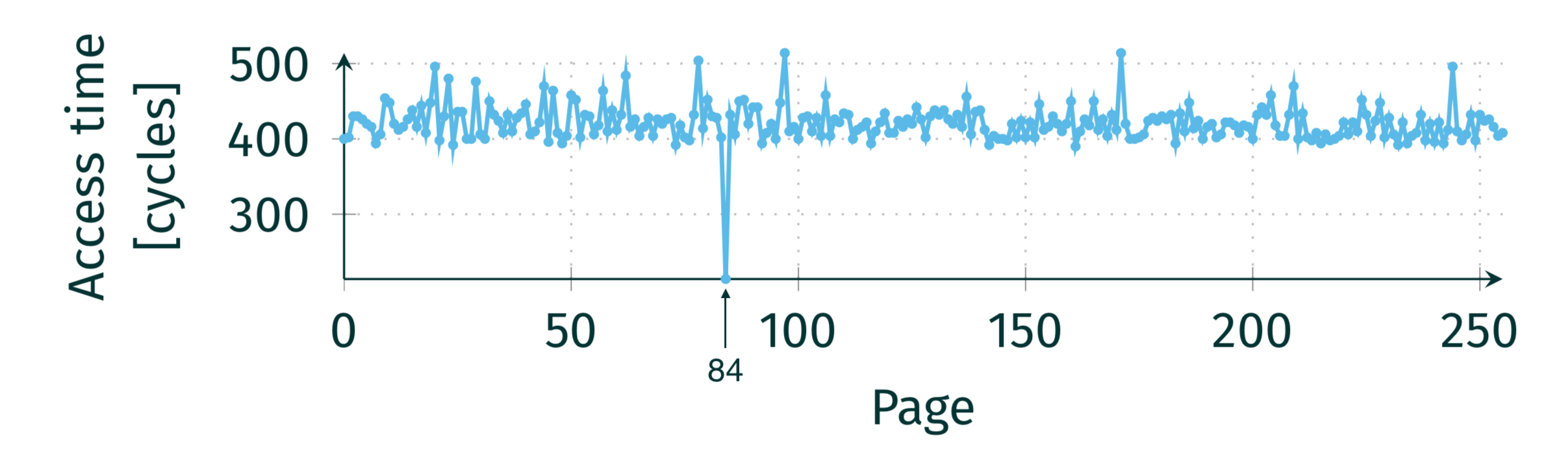
像这样在极短的时间窗口内留下副作用的指令,在论文中被称为暂态执行(Transient Execution),这也是幽灵系列漏洞的核心技术。因为不少主流操作系统都在内核空间中直接映射了物理内存,所以通过暂态执行和缓存旁路攻击能够提取物理内存中的所有数据,危害性极强。
影响范围
| 厂商 | 产品 |
|---|---|
| Intel | 几乎所有在售的 CPU |
| AMD | 未受影响 |
| ARM | 仅 Cortex-A75 受到影响 |
| IBM | z/Architecture 和 Power 架构均受影响 |
| Apple | 所有在售的 Mac 和 iOS 设备 |
对策
-
硬件:重新设计 CPU 以确保在发射读取指令之前进行权限检查,英特尔已于 Coffee Lake Refresh 及后续微架构中修补熔毁漏洞,但之前的 CPU 就只能软件修补了;
-
软件:各大操作系统都推出了内核页表隔离补丁来抵御熔毁漏洞:
- Linux 4.15 已部署 Kernel Page-Table Isolation;
- Windows 10 build 17035 已部署 KVA Shadow;
- macOS 10.13.2 / iOS 11.2 已部署 Double Map;
- ……
内核页表隔离
说起 Linux 这次针对熔毁漏洞的内核页表隔离补丁,其背后还有一段不短的历史,最早要从 Linux 的内核地址空间布局开始说起。
KASLR
最早 Linux 的内核映像在地址空间中的地址是固定的,这使黑客能够硬编码地址对 Linux 进行攻击。为了使这类攻击不容易奏效,Linux 3.14 引入了内核地址空间布局随机化(Kernel Address Space Layout Randomization),也就是说在每次系统启动时可以随机生成一个内核映像地址的偏移量,不过直到 Linux 4.12 开始 KASLR 才被默认开启。
KAISER
虽然 KASLR 增加了攻击的难度,但不能杜绝黑客访问到内核映像。2017 年,格拉茨科技大学的研究人员提出了高效移除旁路的内核地址隔离(Kernel Address Isolation to have Side-channels Efficiently Removed)补丁来进一步加固,恰好这个补丁对后来的熔毁漏洞也十分有效。KAISER 提议内核态和用户态使用两张不同的页表,内核态的页表还跟原来一样,而用户态的页表中不再暴露内核地址空间,除了少量 x86 架构必需的部分。不过其缺点也很明显,切换页表和清空转译后备缓冲器(Translation Lookaside Buffer)带来了不少额外的性能开销。
KPTI
在得知熔毁漏洞之后,Linux 社区开始着手从软件层面进行修补。开发团队在 KAISER 的基础上加入了一些优化,譬如支持进程上下文标识符(Process-Context Identifier)以避免清空页表缓存从而降低性能影响,并将其改名为内核页表隔离(Kernel Page-Table Isolation)最终并入了 Linux 4.15。
幽灵(Spectre)
幽灵漏洞的影响范围比熔毁漏洞更加广泛,影响当下几乎所有计算机系统;不过幽灵漏洞相较而言更难利用,因为它需要被攻击的软件中包含特定形式的可利用代码。
幽灵漏洞的核心也是暂态执行,暂态执行除了前面叙述的乱序执行之外还有其他的触发方式,而幽灵的论文中便提到了两种,这两种均与分支预测有关。因为分支指令可能涉及内存读取,需要上百个时钟周期才能完成,因此现代处理器都设计了分支预测器来预先推测执行。一个解耦的分支预测器通常包含两个部分:
- 分支方向预测器:预测分支的条件是真是假,通常利用模式历史表(Pattern History Table)等进行预测;
- 目标地址预测器:预测间接跳转的目标地址,通常利用分支目标缓冲器(Branch Target Buffer)等进行预测。
幽灵漏洞的步骤与熔毁漏洞类似,也是通过缓存旁路攻击来获取暂态执行泄漏的信息。在攻击之前,通常还会训练分支预测器,使其运行目标代码时会进行特定的预测执行;同时可以把条件判断所需的数据挤出缓存,以提高预测执行发生的概率。
变体一:边界检查绕过
我们设想系统调用或库中有这样一段代码:
if (x < len(array1))
y = array2[array1[x] * 4096];
其中 x 是一个外部传入的变量,所以条件语句进行了数组越界的检查。我们可以训练分支预测器让它暂态执行第二行的代码,则 array1[x] 可以访问任意数据,再对 array2 进行缓存旁路攻击即可。
Spectre-V1 影响几乎所有 CPU,且不仅可以在系统级编程语言中构造,在带即时编译优化的 JavaScript 引擎中亦可复现。因此 Mozilla 宣布从 Firefox 57 开始 performance.now() 的精度将降到 20µs,SharedArrayBuffer 将默认禁用。而英特尔等厂商未推出硬件解决方案,建议开发者从软件层面解决,譬如 ICC 新增 -mconditional-branch=pattern-fix 选项来自动插入 LFENCE 指令避免预测执行。

变体二:分支目标注入
第二个变体则是针对间接跳转目标地址的预测,我们可以训练分支预测器对方法调用等进行错误的目标地址预测,使其暂态执行我们挑选的可利用代码,辅以缓存旁路攻击获取机密数据。
Spectre-V2 同样也影响几乎所有 CPU。英特尔发布了微码更新,引入了三种 Indirect Branch Control Mechanisms,可供对间接跳转预测进行限制。而谷歌工程师提出了 Retpoline,将间接跳转指令替换为返回指令,并将预测执行拖入死循环以缓解漏洞,ICC / GCC / Clang 等各大编译器均已提供支持。譬如 x86 (Intel Syntax) 中的 jmp rax 指令会被 Retpoline 替换为:
1: call set_up_target
capture_spec:
2: pause
3: jmp capture_spec
set_up_target:
4: mov [rsp], rax
5: ret
虽然处理器对于间接跳转目标地址的预测相对复杂,容易被投毒;但对于返回指令目标地址的预测是确定的,主要依赖一个后进先出的返回栈缓冲器(Return Stack Buffer)。在上面的例子中,指令 1 会将指令 2 的地址压入 RSB 中,并直接跳转到指令 4,指令 4 会将原来间接跳转的目标地址写入调用栈中返回地址的位置,于是下一行的返回指令 5 便完成了间接跳转的工作。另一方面,如果处理器进行了预测执行,在指令 5 处它会读取 RSB 并跳转到指令 2,接下来预测执行便陷入了死循环,直到处理器意识到预测并不正确。这样一来,Retpoline 便杜绝了目标地址预测被投毒的可能性。
预兆(Foreshadow)
在全世界计算机安全风雨飘摇的一年里,大家都在寻找更加安全的可信计算环境,而其中经常被提到的便是 SGX。SGX 全称软件保护扩展(Software Guard Extensions),是英特尔处理器的一组扩展指令集。SGX 能够在内存上创建飞地(Enclave),这块空间受到处理器的严格保护,OS / Hypervisor / BIOS 等系统软件亦无法访问,相当于一个硬件级别的沙盒。
可惜的是,SGX 也被熔毁漏洞的变体攻破了,这个变体被称为预兆漏洞。其流程与熔毁漏洞相似,但 SGX 的安全机制使攻击流程多了两步:
- 即使利用乱序执行漏洞,SGX 飞地数据也无法从内存读取,必须预先加载到 L1 缓存才能绕过限制,这也是该漏洞被英特尔官方命名为 L1 Terminal Fault 的原因;
- 对指向 SGX 飞地的指针解引用会返回中止页(Abort Page)使得结果为 -1,而不像之前因访问内核空间而缺页(Page Fault)。为了绕开这个限制,需要调用
mprotect函数将页表项的 Present 位设为无效,从而提前在传统页表检查时便抛出缺页。
预兆漏洞影响英特尔所有支持 SGX 的 CPU,即 Skylake 及其后续微架构,Atom 系列除外。英特尔已经发布了微码更新,后续 CPU 也将进行硬件修复。
系统性分类
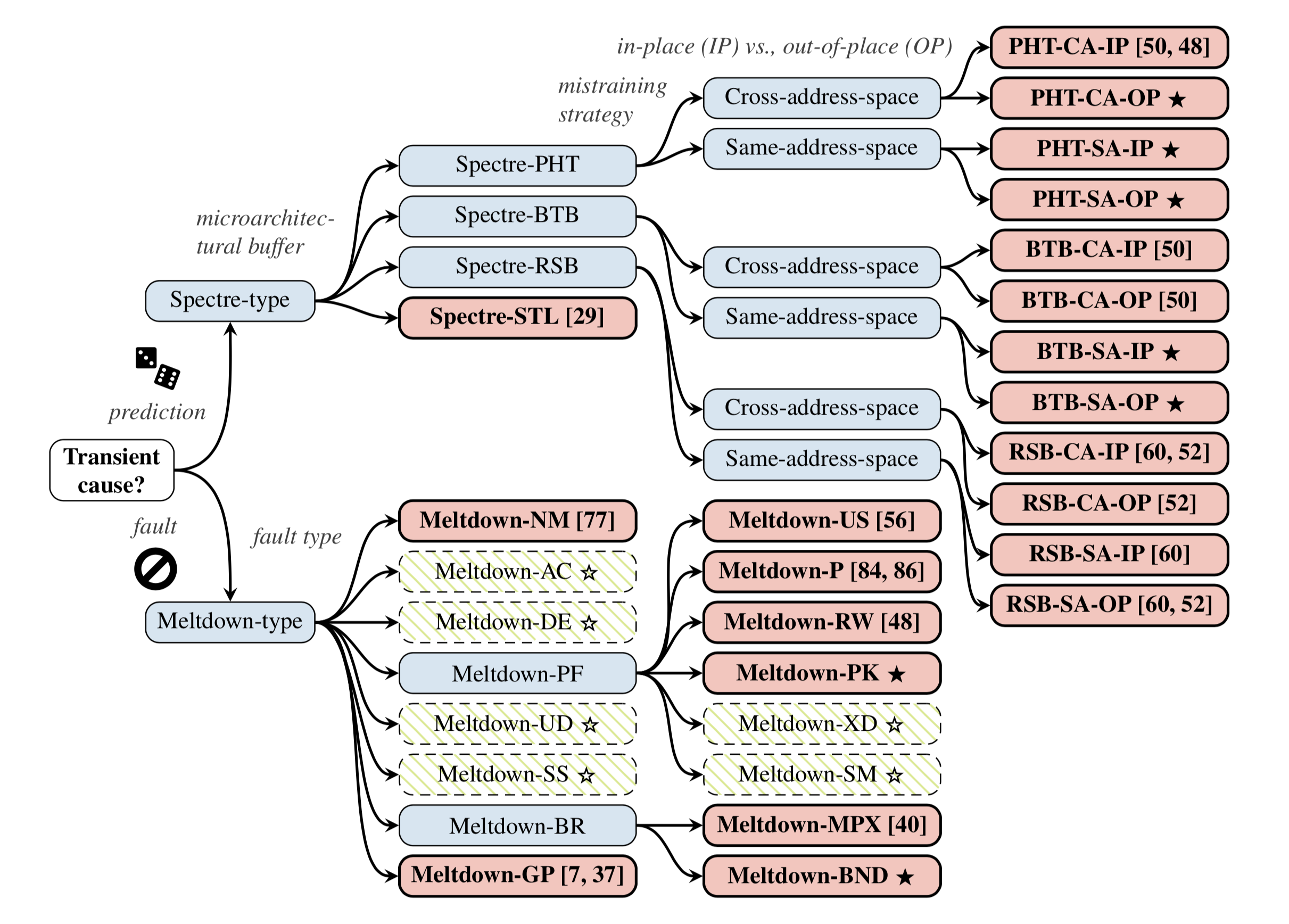
随着幽灵系列漏洞如雨后春笋般不断涌现,格拉茨科技大学的研究人员又撰写了论文对暂态执行攻击进行了系统性分类和梳理分析。首先论文以暂态执行的成因将攻击分为幽灵和熔毁两大类:前者是预测执行的误判,后者是乱序执行对异常的延时处理。
对于幽灵类的攻击,论文以预测执行所依赖的处理器元件进行分类:
- Spectre-PHT:利用的是进行分支方向预测的模式历史表,包括 Spectre-V1、Spectre 1.1、NetSpectre;
- Spectre-BTB:利用的是进行目标地址预测的分支目标缓冲器,包括 Spectre-V2;
- Spectre-RSB:利用的是进行返回地址预测的返回栈缓冲器,包括 SpectreRSB、ret2spec;
- Spectre-STL:利用的是进行内存依赖预测的 store-to-load 转发,包括 Spectre-V4。
对于熔毁类的攻击,论文首先以异常类型分类,如果利用的异常是缺页则再基于页表项的属性位进行二级分类:
- Meltdown-GP:使用
RDMSR等指令非法读取系统寄存器会触发一般保护错误(General Protection Fault,#GP),利用这个异常进行暂态执行的攻击是 Spectre-V3a; - Meltdown-NM:FPU 的 SIMD 寄存器很大,然而不是所有进程都会用到它们,所以基于性能考虑,英特尔处理器没有在每次上下文切换的时候都保存和恢复这些寄存器。当新的进程第一次访问这些寄存器时,会触发设备不可用错误(Device Not Available,#NM),此时才会将它们保存进上一个进程的上下文中。利用这个异常进行暂态执行的攻击是 LazyFP;
- Meltdown-BR:现代处理器通常支持
BOUND指令来进行数组越界的检查,更新的还有英特尔的扩展指令集 MPX,它们都会在数组越界时触发越界错误(BOUND Range Exceeded,#BR),论文在英特尔和 AMD 的处理器上成功实施了基于该异常的攻击; - Meltdown-PF:基于缺页(Page Fault,#PF)的暂态执行攻击;
- Meltdown-P:如前文所述,Foreshadow 和 Foreshadow-NG 为了绕开 SGX 的限制,通过将页表项的 Present 位设为无效引发缺页;
- Meltdown-RW:Spectre 1.2 指出可以在暂态执行期间无视 Read/Write 位对只读数据进行写入;
- Meltdown-US:元祖 Meltdown,利用了 User/Supervisor 位引发的缺页;
- Meltdown-PK:英特尔的 Skylake-SP 服务器处理器支持了 Memory Protection Keys for Userspace,可在用户空间更改页的权限,但论文提出该权限控制可通过暂态执行绕过。
论文中还分析了一些可能存在但实际上未能成功的攻击种类,在这里就不一一赘述了。
参考论文
- Paul Kocher, et al. Spectre Attacks: Exploiting Speculative Execution. 40th IEEE Symposium on Security and Privacy. San Francisco, USA. May 20-22, 2019.
- Moritz Lipp, et al. Meltdown: Reading Kernel Memory from User Space. 27th USENIX Security Symposium. Baltimore, USA. August 15-17, 2018.
- Van Bulck, et al. Foreshadow: Extracting the Keys to the Intel SGX Kingdom with Transient Out-of-Order Execution. 27th USENIX Security Symposium. Baltimore, USA. August 15-17, 2018.
- Claudio Canella, et al. A Systematic Evaluation of Transient Execution Attacks and Defenses. arXiv:1811.05441.
- Daniel Gruss, et al. KASLR is Dead: Long Live KASLR. 9th International Symposium on Engineering Secure Software and Systems. Bonn, Germany. July 4-5, 2017.
- Daniel Gruss, et al. Kernel Isolation: From an Academic Idea to an Effective Patch for Every Computer. USENIX ;login: Winter 2018.
- Oliverio J. Santana, et al. A Comprehensive Analysis of Indirect Branch Prediction. 4th International Symposium on High Performance Computing. Kansai Science City, Japan. May 15-17, 2002.